
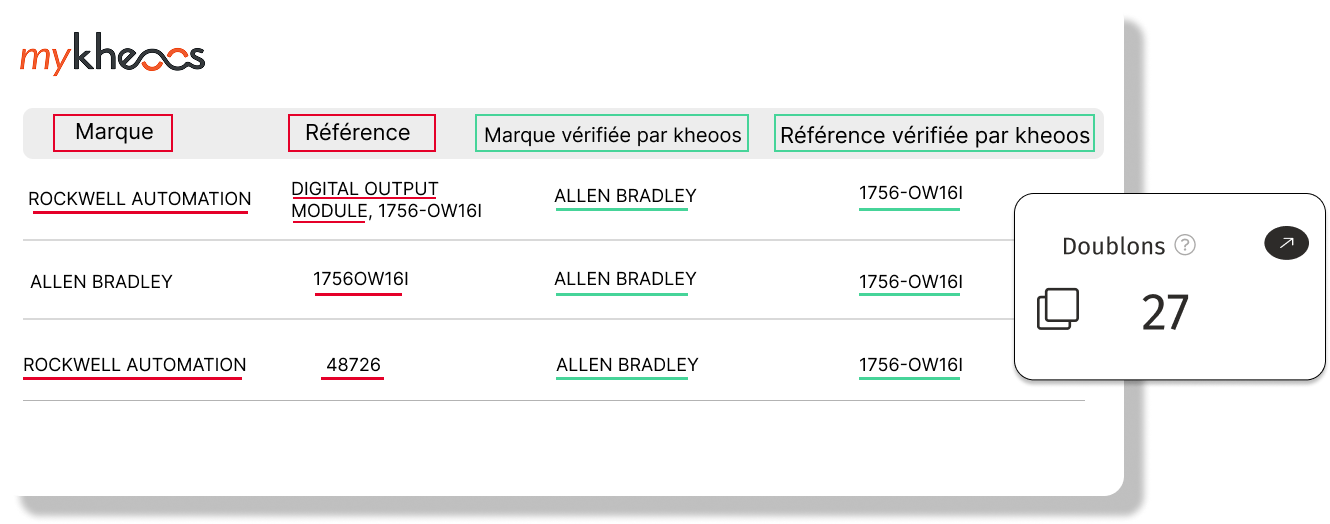
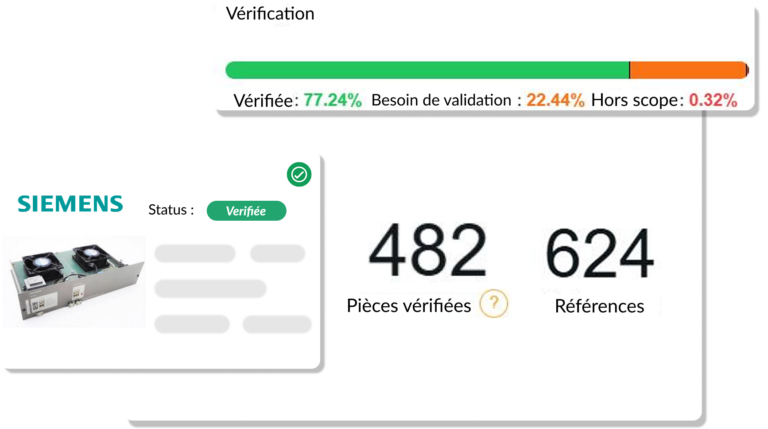
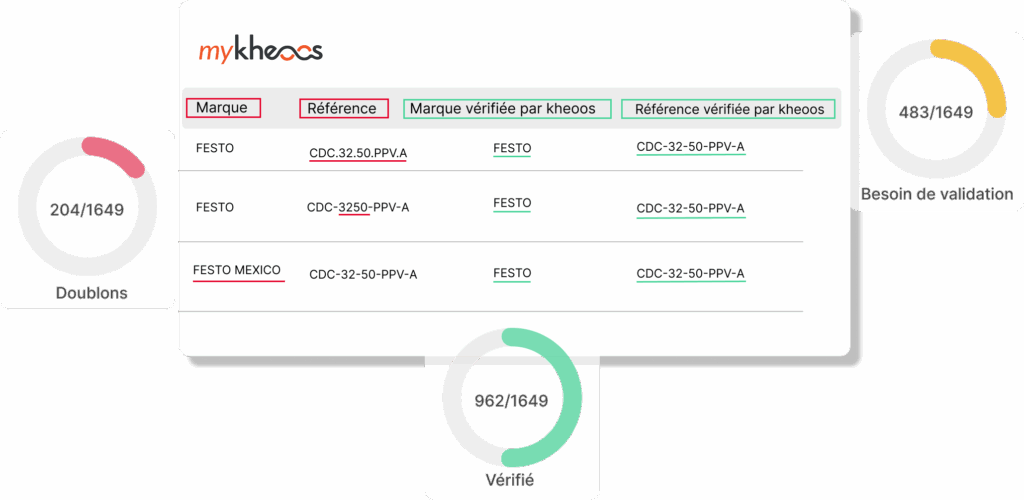
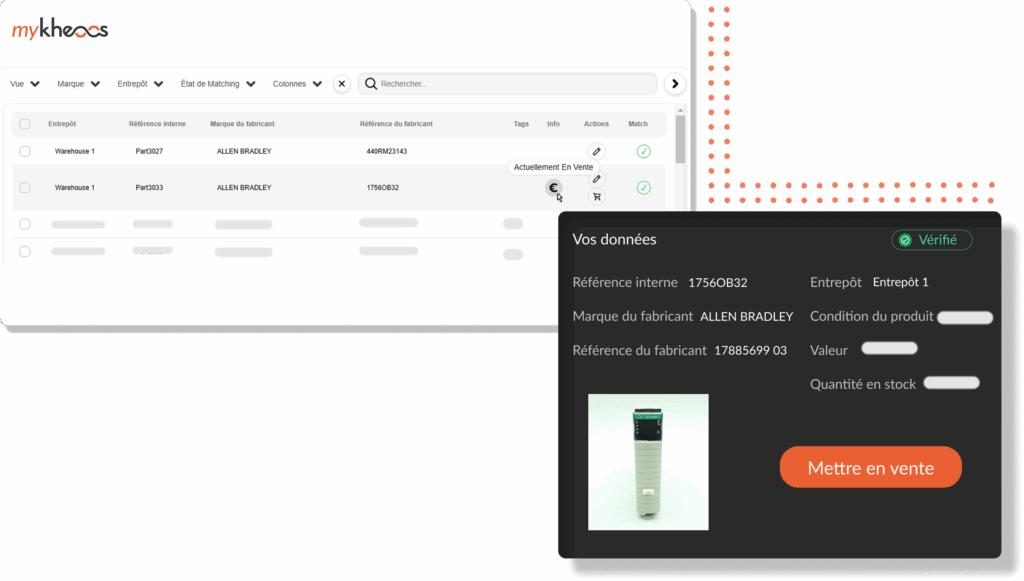
"Para limpar a base de dados, estava previsto o trabalho de 2 funcionários a tempo inteiro durante 20 anos... Com a kheoos, bastaram apenas 18 meses."
Alexandre OrtigierComprador empresa EEE, Michelin 
"Com a kheoos, foi possível evitar mais de 981kg de resíduos nos stocks parados."
Damien BarrraudGestor de Projeto de Fabricação Inovadora na EDF 
"A linha de produção estava parada. Graças ao mykheoos, foi possível localizar imediatamente as peças essenciais noutra unidade do grupo e retomar a produção sem demora."
Philippe PeronResponsável de manutenção, Episens 















