
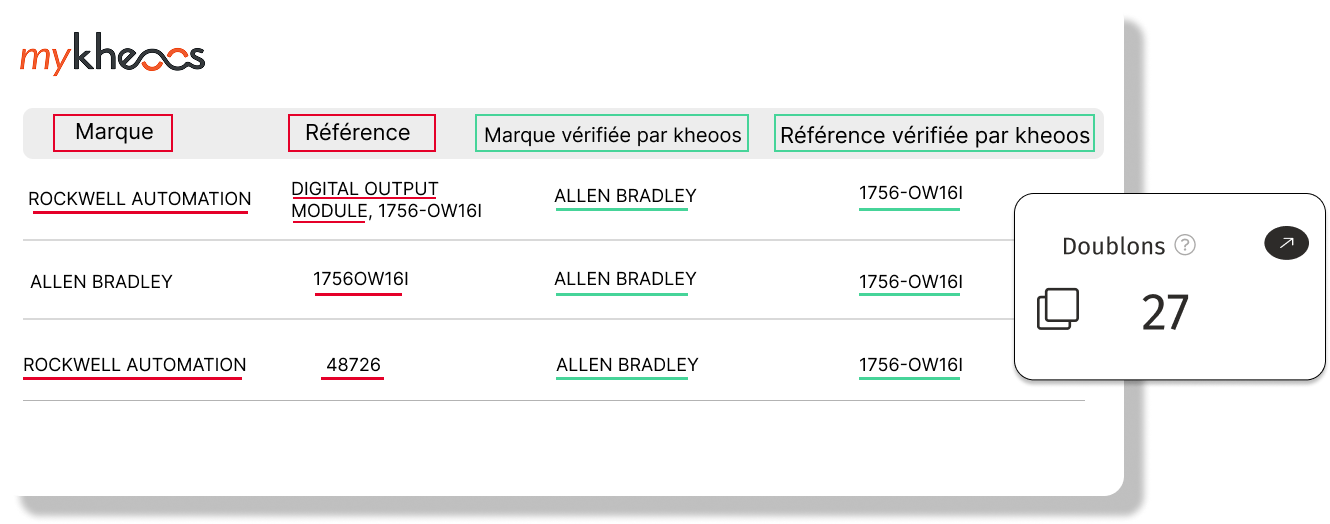
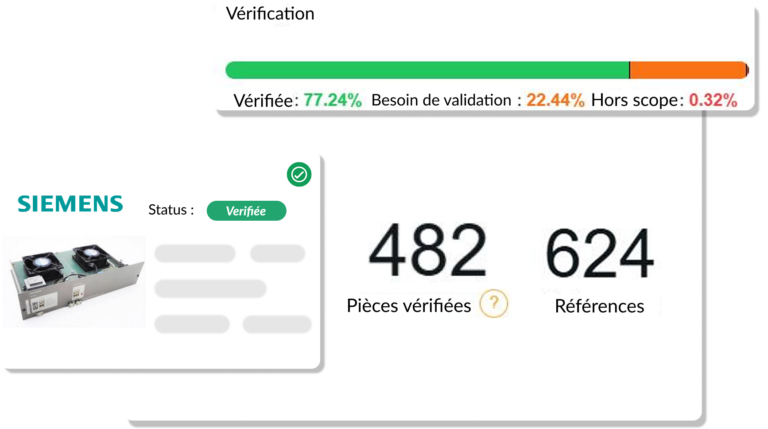
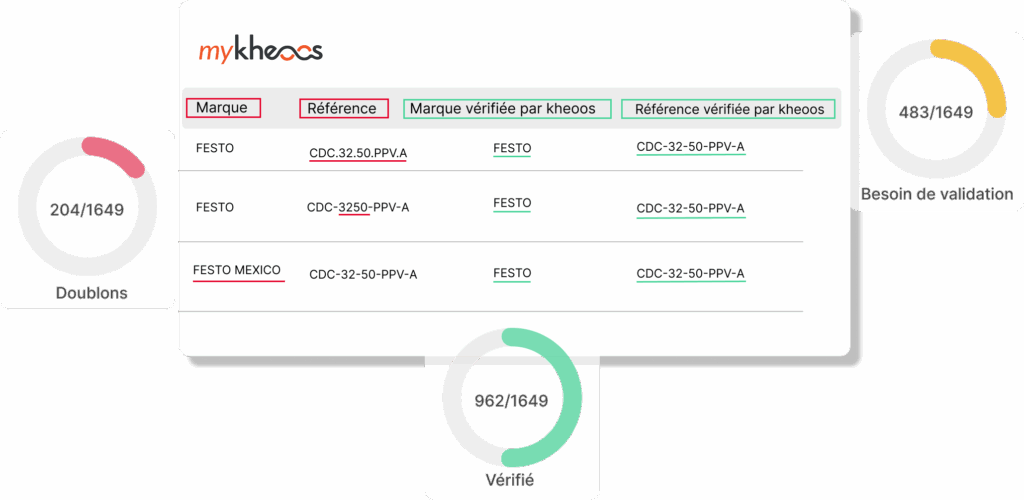
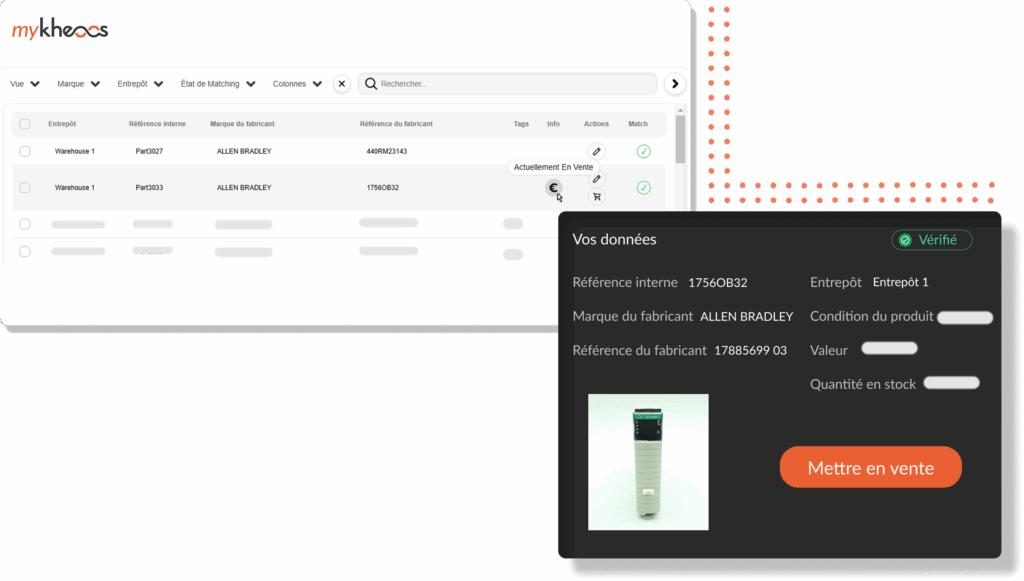
„Pentru curățarea bazei de date, s-au estimat 2 angajați cu normă întreagă timp de 20 de ani... Cu kheoos, a fost nevoie de doar 18 luni.”
Alexandre OrtigierAchizitor companie EEE, Michelin 
„Cu kheoos, au fost evitate peste 981 kg de deșeuri din stocurile inactive.”
Damien BarrraudManager proiect fabricație inovatoare, EDF 
"Linia de producție era oprită. Datorită mykheoos, piesele esențiale au fost localizate imediat într-o altă fabrică a grupului, iar producția a fost reluată fără întârzieri."
Philippe PeronResponsabil mentenanță, Episens 















