
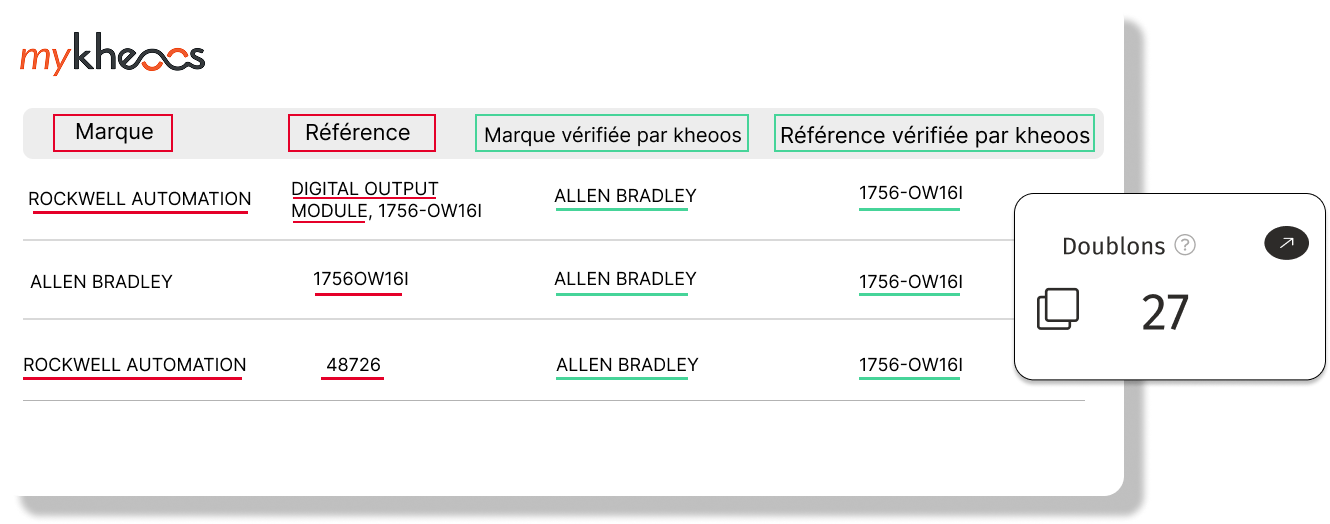
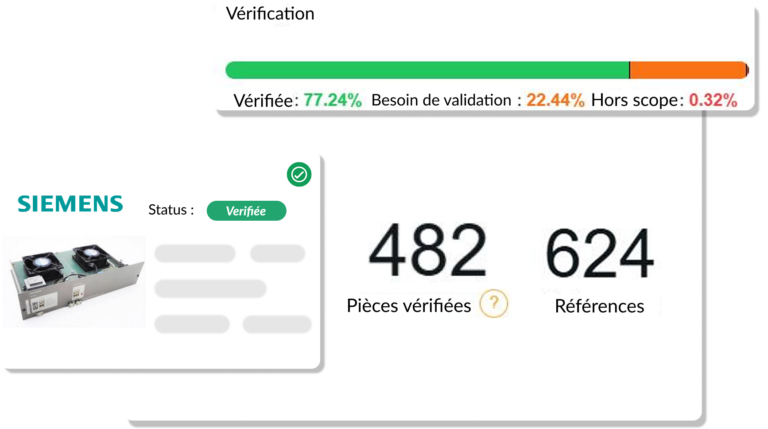
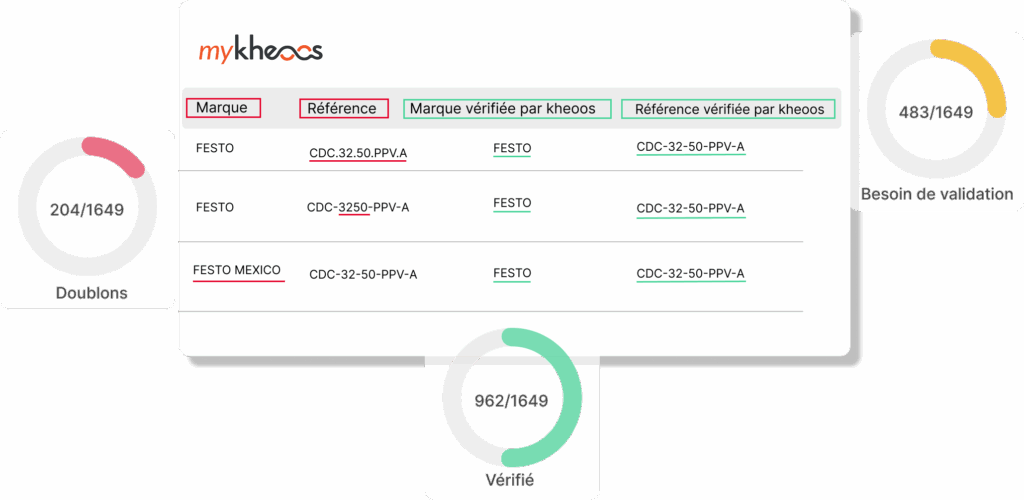
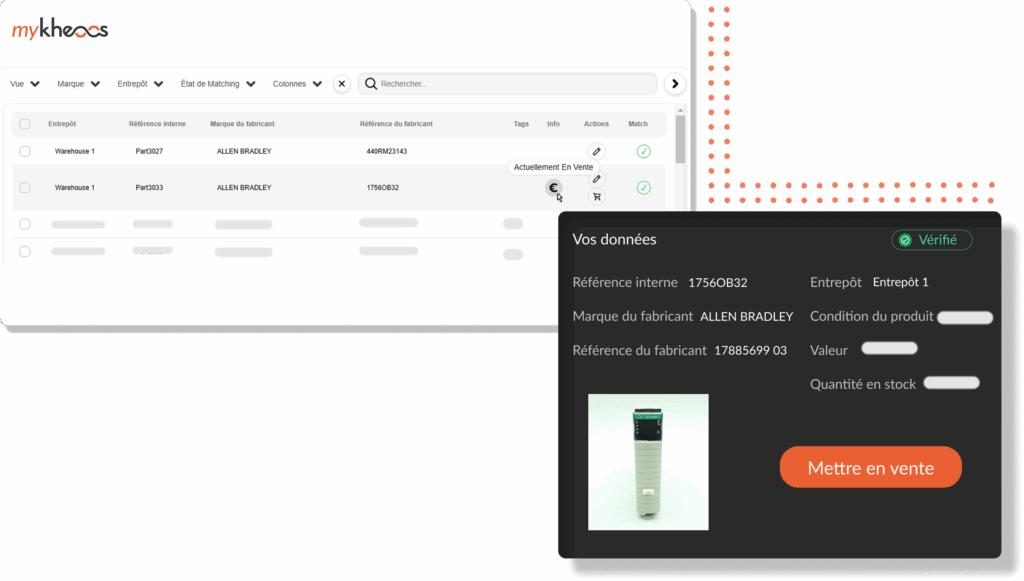
« Щоб очистити базу даних, оцінювали необхідність роботи двох співробітників протягом 20 років... Завдяки kheoos це зайняло лише 18 місяців. »
Alexandre OrtigierЗакупівельник компанії EEE, Michelin 
« Завдяки kheoos вдалося уникнути понад 981 кг відходів серед неактивних запасів. »
Damien BarrraudКерівник проєкту інноваційного виробництва, EDF 
« Лінія виробництва була зупинена. Завдяки mykheoos вдалося негайно знайти необхідні запчастини на іншому підприємстві групи й без затримки відновити виробництво. »
Philippe PeronМенеджер з технічного обслуговування, Episens 















